今回は評価関数について、深掘りです。適切な評価関数にしてあげることで、機械学習の良し悪しが決まってくると思います。
Contents
どこで使うのか?
私は機械学習のちょっと前で、get_evaluateという名前でメソッドを定義することにしています。
メソッドの中身は最終的に数行になるのでわざわざ分ける必要もないかもしれないですが、メソッドにしておくと流用可能ですし、改変も楽です。
機械学習が終了後、メソッドを呼び出して、今回の評価をprintします。
使いどころとしては、KFoldなどのクロスバリデーションをする際に結果の良し悪しを判断するために使っています。
# 評価関数
def get_evaluate(y_test, predict):
・・・・・
return value
# 機械学習
lgb_train = lgb.Dataset(X_tr, y_tr, categorical_feature=categorical_features)
lgb_test = lgb.Dataset(X_test)
params = {
'objective': 'regression',
'metric': 'rmse',
}
model = lgb.train(params, lgb_train, 100)
y_predict = model.predict(X_va, num_iteration=clf.best_iteration)
rmse= get_evaluate(y_va, y_predict)
print('rmse:{}'.format(rmse))今回は、get_evaluateの中身を作ることにします。
メソッドの中身
作成した中身のコードはこちらです。
from sklearn import metrics
# rocの時
def get_evaluate(y_test, predict):
roc = metrics.roc_auc_score(y_test, predict)
return roc
# rmseの時
def get_evaluate(y_test, predict):
rmse = np.sqrt(metrics.mean_squared_error(y_test, predict))
return rmse実際の目的値(y_test)と機械学習で予測した値(predict)をメソッドで受け取って最終的に計算した値を返しています。
rocとは
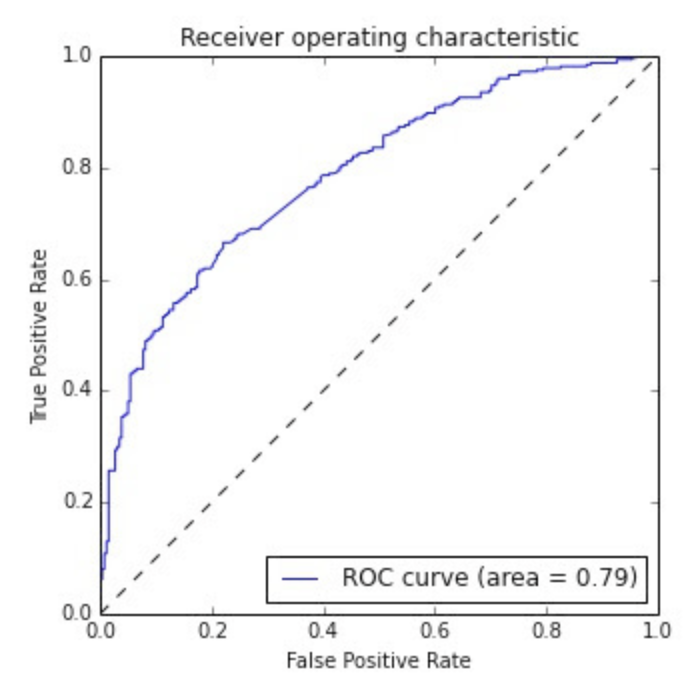
rocは縦軸に真を真に予測できた割合、横軸に偽を偽に予測できた割合をとって、プロットしたものです。
カーブした形のものになり、roc curveと呼ばれたりします。
分類問題などで使われます。
https://signate.jp/competitions/1#evaluation
機械学習などで適当に予測したら、ちょうどグラフの真ん中一直線(評価値0.5)になります。
評価値(0.5)を下回っていた場合は、分類の結果をひっくり返せば高評価値になります。
metrics.roc_auc_scoreで簡単に計算することができます。
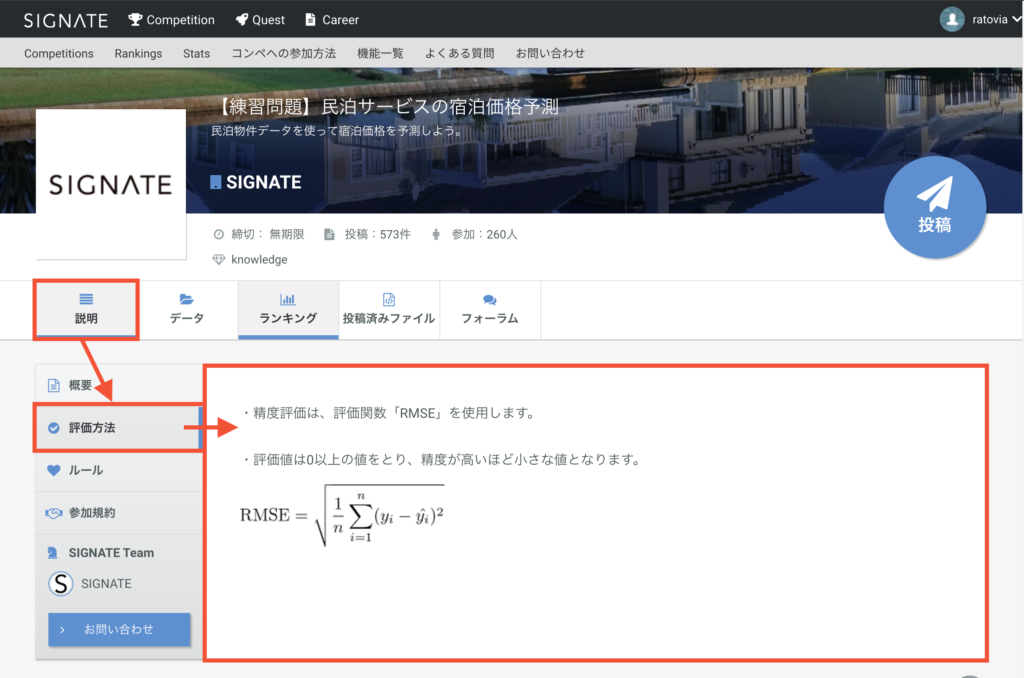
rmseとは
二乗平均平方根誤差といい、以下の式で計算できます。

https://signate.jp/competitions/266#evaluation
簡単に解説すると、実際の値と予測した値の差を2乗したものを行ごとに出して、全部の行を見たときの平均値となります。
評価値は小さい方が高評価となります。
完璧に予測できた場合、評価値0になります。負の値はとりません。
np.sqrt(metrics.mean_squared_error(y_test, predict))で計算できます。
コンペに最適な評価手法の確認方法
それぞれコンペにて、コンペ側が最終的にどうやって評価するかを記載しているでしょう。
なので、私たちがプログラミングする際も同じ評価関数で予測した方がいいと思います。
kaggleとSIGNATEの確認方法です。SIGNATEは日本語なのでわかりやすいですね。
lightgbmのobjectiveとmetrics
lightgbmのparamsには様々なパラメータを渡せます。
代表的なのがobjectiveとmetricsだと思います。
params = {
'objective': 'regression',
'metric': 'rmse',
}
model = lgb.train(params, lgb_train,100)回帰問題の場合は、'objective': 'regression'
分類問題の場合は、'objective': 'binary'
と設定します。
‘metric’は、lightgbmが機械学習する際の学習評価手段ですね。
二乗平均平方根誤差の場合は、'metric': 'rmse'
rocの場合は、'metric': 'auc'
と設定します。
aucというのは、roc curveの下側の面積です。
[…] lightgbmの評価関数(roc、rmse) […]
[…] RMSEについてはこちら […]